自动驾驶中,激光雷达点云如何做特征表达
文章来源: 计算机视觉之路
发布时间:2020-05-02
激光雷达在自动驾驶系统中起着关键作用。
激光雷达在自动驾驶系统中起着关键作用。利用它,可以准确地对车辆所处环境做3D建模,如高精度地图;也可以准确知道某个3D目标在激光雷达坐标系中的位置、大小及姿态,即:3D目标检测。
在介绍点云特征表达之前,先介绍一下自动驾驶车辆使用的激光雷达成像原理。
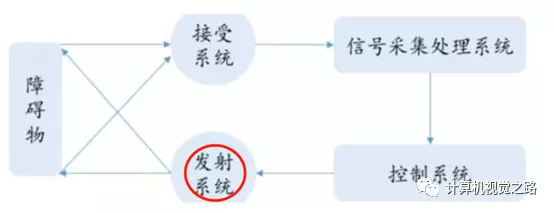
激光雷达是一种综合的光探测与测量系统,通过发射接受激光束,分析激光遇到目标对象后的折返时间,计算出目标对象与车的相对距离。目前常见的有16线、32线、64线激光雷达。激光雷达线束越多,测量精度越高,安全性越高。工作原理如图所示:
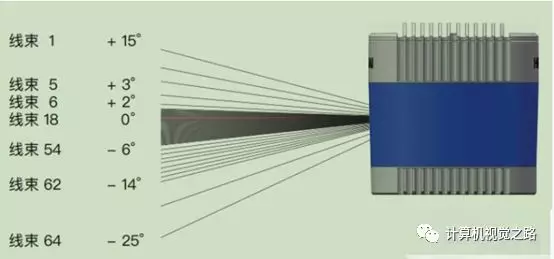
多束激光线同时发射,并配合激光雷达的旋转便得到了如上图所示的激光雷达点云。其中激光雷达的线束决定了传感器的垂直视角以及垂直方向的分辨率,如下图所示为禾赛64线激光雷达,其垂直方向最多有64根线,且视场范围为:-25°~+15°。旋转速度决定了水平方向点云角分辨率,如:激光雷达扫描频率为10Hz,水平角分辨率为0.2°,那么扫描的点数为360°/0.2°=1800点;若扫描频率提高到20Hz,此时角分辨率为0.4°,扫描点数也就减半,同样目标上的点云会更稀疏。
激光雷达的稀疏点云成像与稠密像素点的图像成像不同,点云都是连续的,图像是离散的;点云可以反应真实世界目标的形状、姿态信息,但是缺少纹理信息;图像是对真实世界的目标离散化后的表达,缺少目标的真实尺寸;图像可以直接作为cnn网络的输入,而稀疏则需要做一些预处理。
因此,为了完成3D目标检测任务,需要对稀疏点云做特征表达,这里介绍3种方式:1)离散化后,手动(hand-crafted)提取特征,或者利用深度学习模型提取特征;2)点对点特征(point-wise feature)提取;3)特征融合。
根据激光雷达的成像原理,可以有两种离散化方式,一种基于旋转平面(即激光坐标系下的xy坐标平面)离散化,可以得到BEV(bird‘s eye view)图,另一种在垂直方向离散化(即z轴),可以得到Camera view的图。
BEV图由激光雷达点云在XY坐标平面离散化后投影得到,其中需要人为规定离散化时的分辨率,即点云空间多大的长方体范围(Δl*Δw*Δh)对应离散化后的图像的一个像素点(或一组特征向量),如点云20cm*20cm*Δh的长方体空间,对应离散化后的图像的一个像素点。根据长方体空间中点云点特征表达方式不同可以分为hand-crafted feature、voxel-feature
使用这种方式做特征表达的典型3D目标检测方法有MV3D、PIXOR、YOLO3D等,通过使用一些统计特征来完成对长方体中点云的特征表达,主要特征包括:最大高度值、与最大高度值对应的点的强度值、长方体中点云点数、平均强度值等。
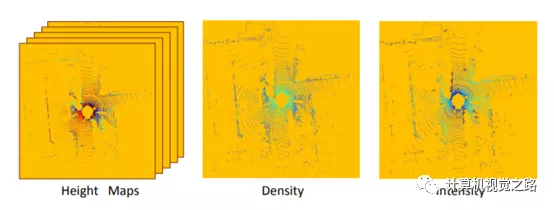
hand-crafted feature主要问题是丢弃了很多点云的点,缺失了很多信息。当然可以通过设置比较小的长方体范围来弥补,但是同时会增加计算量。如下图所示,通过设置比较小的Δh,MV3D得到了一系列的height maps。
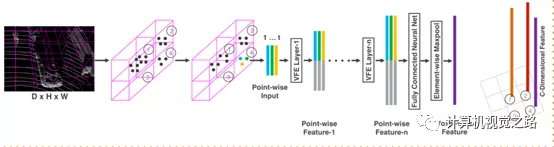
为了使用更多的点信息,以及使用end-to-end模型提取更好的特征,提出了voxel表达方式,广泛应用于second、voxelnet、pointpillar等方法中。voxel的特征表达主要包括3个步骤:点云预处理、点特征表达、voxel特征表达得到BEV图,以voxelnet中的VFE layer为例进行介绍。如下图所示。
-
点云预处理:在一个voxel中筛选一定量的点,在点云原始信息基础上,提取一些相对位置信息,组合成新的点云单点特征表达。
-
点特征提取:使用全连接网络提取单点特征,再计算voxel中筛选出来的点云特征的max-pooling,得到上下文特征,与单点特征组合得到新的点云单点的特征表达。
-
voxel特征表达:经过多步的点特征提取后,将最后一次max-pooling得到的特征向量作为一个voxel的特征表达,对应到BEV图中相应坐标下的特征向量。
在voxelnet原文中,一个voxel大小为20cm*20cm*40cm,其中Δh=40cm,而BEV图的高度范围为400cm,从而在同一个xy坐标点,高度方向上也会产生多个voxel,这种方式会增加后面网络的计算量。因此,在pointpillar中,增大了Δh的值,从而几个voxel成为了一个pillar,如在pointpillar实验中,pillar高度为400cm,对应voxelnet中10个voxel,大大提高了整个网络的计算效率。
基于voxel的特征表达,极大的缓解了点云在做BEV投影时信息丢失的问题,提高了整个网络的效果。
在这种离散化方式中,激光雷达的垂直分辨率(线数)和水平分辨率(旋转角分辨率)是两个重要的可以依据的参数,分别对应了离散化后的图像的高和宽,如对于一个64线,角分辨率0.2°,10Hz扫描频率的激光雷达,离散化后的图像大小为64*1800*c。
根据激光雷达的硬件配置,每条激光线都有固定的垂直方向的角度θ,通过计算θ便可以得到某个点云点对应的离散化后的图像的横坐标;通过计算水平方向的旋转角度ψ,便可以得到某个点云的点对应离散化后的图像的纵坐标,具体计算方式为:
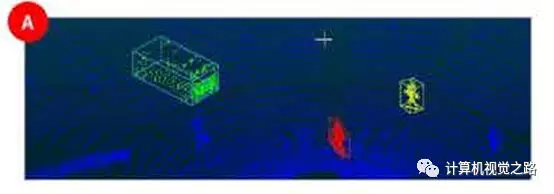
投影效果如下图所示,图A为原始的激光雷达点云,图B为一系列的camera-view的图像,每张图为camera-view图中的一个channel,表达了点云不同的特征,如intensity,x坐标,半径r。
这种投影方式和图像成像效果很相似,如图C,所以称为camera-view,但也同时会引入图像成像的缺点,如遮挡、缺失深度信息等
点对点特征(point-wise feature)提取
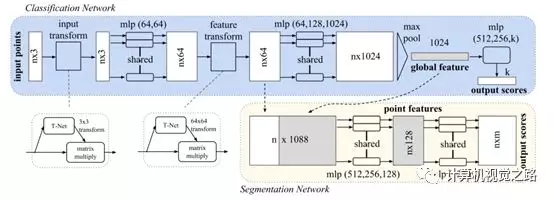
说到point-wise feature,首先想到的是pointnet系列,如下图为pointnet的处理流程,主要包含两个模块: 全连接(mlp)和特征变换(transform)。pointnet特征提取应用在自动驾驶的激光雷达3D目标检测中时,都是简化的版本,比如voxelnet中的VFE layer,很少有pointnet直接作为目标检测的主网络结构,一般仅作为特征提取的方式。在其他应用领域中,pointnet可以作为主要网络做不同的任务,如kaiming大神的Vote3D使用pointnet++做3D目标检测。
自动驾驶中激光雷达的点云比较稀疏,应用在稠密点云的特征表方法可以借鉴,很难直接使用。另外,大部分point-wise特征提取的方法,只能融合局部信息的特征,与更广的上下文信息的联系比较弱,而BEV或者camera view的表达方式,在使用合适的网络结构做特征提取时,感受野可以覆盖全图。因此,在自动驾驶领域,point-wise特征不会直接用来做3D目标检测任务。
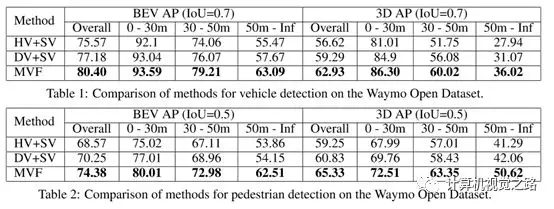
其实,不同的激光雷达点云特征提取方法有各自的优缺点,但联合在一起使用时,能发挥更好的作用,如在waymo的文章“End-to-End Multi-View Fusion for 3D Object Detection in LiDAR Point Clouds”中,融合了不同的特征表达方式,对小目标和远处目标的检测效果增益很大,结果如下图所示,具体融合方式和网络结构可以参考原文。

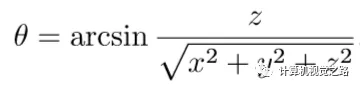
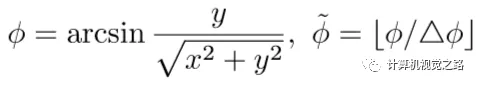















获取更多评论