FPGA+CPU架构的自动驾驶平台性能分析
文章来源:智能汽车设计
发布时间:2022-03-03
本文将以Xilinx 推出的Zynq UltraScale+ MPSoC ( Part#=ZU19EG )为例,来阐述其方法。
由于在自动驾驶领域需要对传感器的数据作大量的基于深度内神经网络的复杂运算,GPU和FPGA被不约而同地用来作为对CPU的一种加速器被使用。这样做不仅可以提高计算性能,并且可以大幅度地降低能耗。FPGA+CPU架构的自动驾驶平台凭借其灵活性,高效率,低能耗等特点,正越来越多地被一大批拥有技术实力的公司使用,比如Waymo,百度,福特,通用等。
在这里本文试图探讨如何对FPGA+CPU自动驾驶平台的性能进行估计,目的是希望帮助开发者在选择FPGA+CPU自动驾驶系统平台时初步掌握一种对系统性能的评估方法。
本文将以Xilinx 推出的Zynq UltraScale+ MPSoC ( Part#=ZU19EG )为例,来阐述其方法。
由于作者知识水平和写作方法的局限,如读者能指出错误纰漏之处,将万分感谢。
二、基于FPGA+CPU的自动驾驶平台系统设计
图一 是比较典型的基于FPGA+CPU的自动驾驶系统原理图。一般来说配置一个多核的应用处理器单元-Application Processor Unit(简称AP)用来跑一个或者多个操作系统,主要用来任务调度,管理等工作,而大数据的处理:比如图像的特征值提取,目标类别识别,多目标跟踪,运动预测等复杂运算多放在FPGA 的可编程逻辑模组Programmable Logic(简称PL)来处理。
1、系统对大数据的处理能力,在这里就是要了解FPGA的PL模组的运算能力。
2、复杂多任务的处理能力,即应用处理器CPU的运算能力。
3、高速海量数据的传递,即传感器的数据接收,以及PL和AP之间的数据通讯能力。
由于篇幅原因,本文将只对第1点进行详细叙述,而第2,3点只做简单叙述。
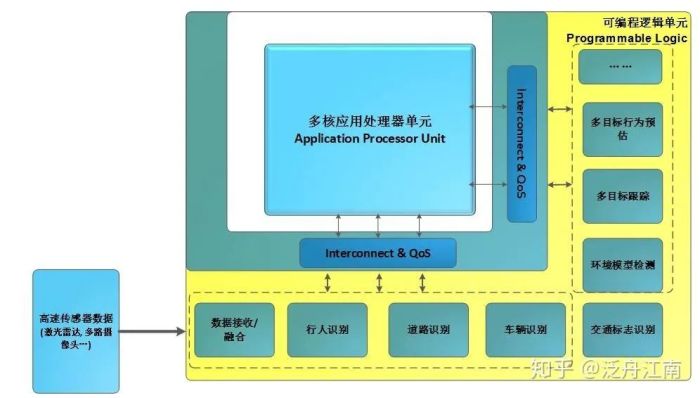
图一:基于FPGA+CPU的自动驾驶平台原理图
三、如何计算FPGA PL的性能
3.1 FPGA 性能难以计算
在介绍如何计算FPGA的性能之前,我们来了解一下目前主流的FPGA的硬件。以Xilinx的Zynq UltraScale+ MPSoC为例,其PL包含可编程资源 Logic blocks, RAM, DSP slices等。
而要得到最终的FPGA 性能值,由于以下几点原因而变得困难。
-
不太容易知道需要多少个logic cell和DSP slice才能构造成一个加法器。这个数量是FPGA IP core供应商决定的,用户难以知晓。
-
通常FPGA用来实现和Application processor通讯的I/O设备需要占用一定数量的Logic cell,导致FPGA 资源不可能全部被利用到构造加法器。
-
浮点运算会导致设计的clock无法达到100%的设计指标,相对于设计的clock频率指标,只能达到在80%左右
-
温度影响也要求系统的clock必须作出调整而不能以一个固定的值来计算
3.2 一种PFGA性能计算方法
目前通常使用的方法是参考系统的每秒浮点运算操作(floating-point operations per second ),简称FLOPS。因为浮点运算用到的所有的高阶函数,比如除法,平方,三角函数等,都能归结为加法,乘法运算,且常用的傅里叶变换,矩阵操作也都可以用加法器(adder)和乘法器(multipliers)的组合来实现,所以FLOPS和加法器/乘法器的数量在衡量其运算性能上是直接关联的。
为了计算FPGA的最大运算能力,我们可以通过利用单精度(Single-Precision)数据加法器数量的方法来求出一个系统的FLOPS。较乘法器而言,加法器利用到的系统资源少,求出的系统FLOPS的值就会接近最大值。
假设所有的运算都是并行的,那么可以得到下面的FLOPS计算公式:
FPGA PL FLOPS = ( Clock1 x LC based Adder#) + ( Clock2 x DSP48 based Adder#)
根据以上公式,下面我们以Xilinx的Zynq UltraScale+ MPSoC的ZU19EG为例,来求其FLOPS.
3.3 FPGA的总资源
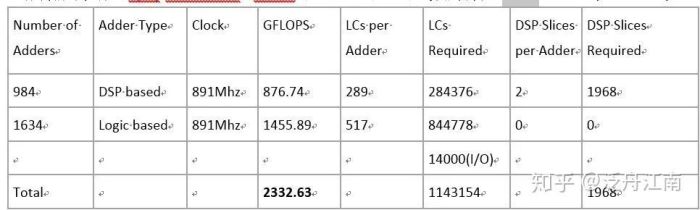
由图二,Zynq UltraScale+ (Part=ZU19EG) 拥有的资源列表,我们可以看到它有1,143,450个Logic cell, 1,968个DSP slices。
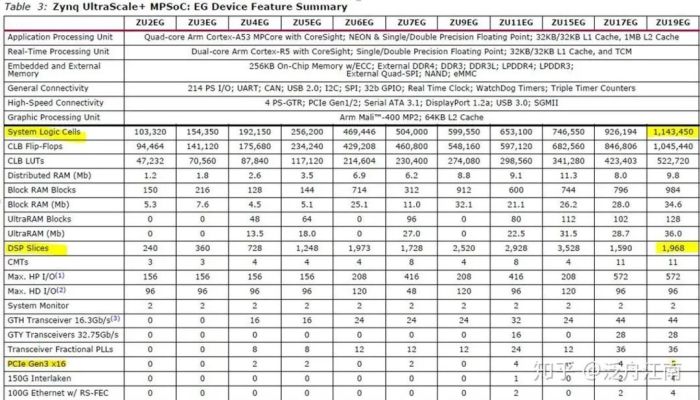
图二:Xilinx Zynq UltraScale+资源列表
3.4 PL加法器数量的计算
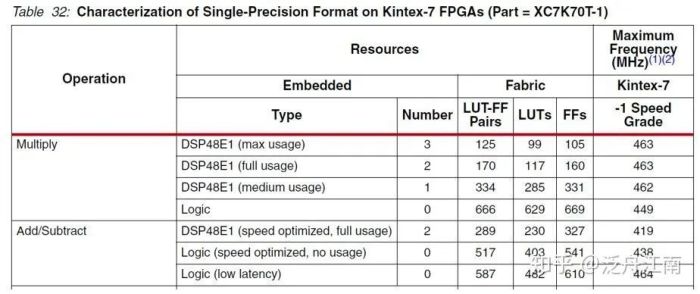
IP Core的实现方式由算法供应商决定,在这里仅以Xilinx提供的基于Kintex-7上的加法器IP Core用到的资源作为参考,误差应该在可接受范围。如图三,可以得知:
-
1个基于DSP48E 的加法器需要2个DSP slices和289LUT-FF pairs组成
-
1个基于Logic cell 的加法器需要517 Logic Cells组成
由于实现相关的I/O设备,必须占用掉一定数量的Logic Cell,这里我们假设用掉14000个Logic Cell. 也即:Logic Cell 剩下总数 = 1143450 - 14000 = 1129450
由于要计算出最大值,我们需要假设尽可能多的使用所有资源,这样可以得出:
-
DSP48 based adder amount = 1968 / 2 = 984 (个)
-
LC based Adder amount = (1129450 - 984*289) / 517 = 1634(个)
3.5 加法器的Clock
-
基于DSP48 的加法器的clock范围在:600 Mhz(slow) - 891Mhz (fastest)
-
基于Logic cell的加法器的clock范围在:667 Mhz(slow) - 891Mhz (fastest)
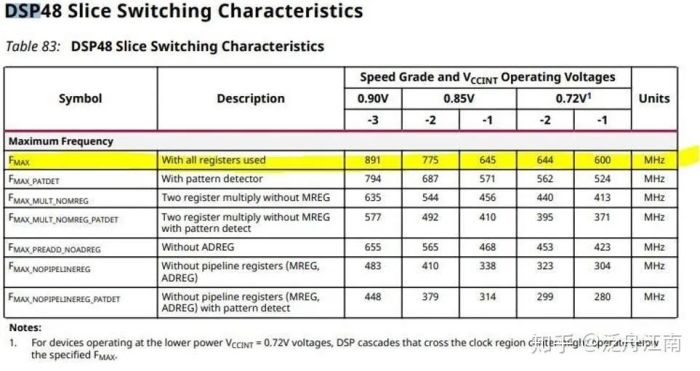
图四 DSP slice 频率参数特征
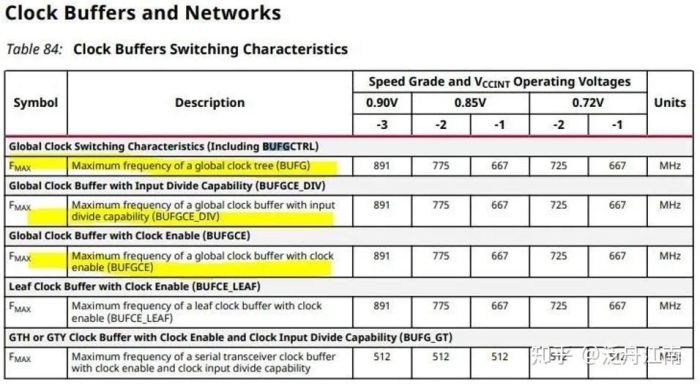
图五 Global 时钟参数特征
根据不同的温度条件,Fmax的值需要相应调整。比如:
-
当温度条件在0-100度时,给加法器设置的clock可以设置较高为891Mhz,
-
当温度条件在-40-100度时,给加法器设置的clock需要调整为600Mhz/667Mhz,
为了计算最大运算能力,我们采用在0-100度的条件下的clock值,也就是891MHz.
图六 各个模组算力一览
这样我们可以得出Zynq UltraScale+ MPSoC的ZU19EG的PL的运算能力为:
总结: ~2T FLOPS某种程度上反映了FPGA Zynq UltraScale+ ZU19EG PL的处理能力。如果针对汽车级别产品而言,-40度至100度温度的限制,整体PL的 FLOPS值应该在1 FLPOS - 1.5T FLPOS之间比较恰当。
四、如何计算FPGA AP的性能
如图七,Xilinx的MPSoc+FPGA系列产品则完全可以叫SoC了,其不仅包含多个ARM CPU内核,还有针对安全领域的R5内核,还有Mali 400这样的GPU。
从下面的图,可以得知FPGA Zynq UltraScale+ ZU19EG拥有
-
CPU#1:Quad-coreARM® Cortex™-A53 MPCore™ up to 1.5GHz
-
CPU#2:Dual-coreARM Cortex-R5 MPCore™ up to 600MHz
-
GPU:Mali™-400 MP2 up to 667MHz
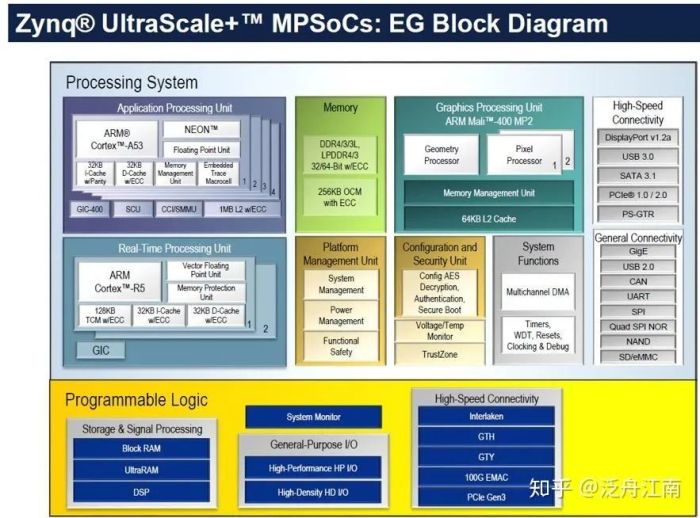
图七 Xilinx FPGA Zynq UltraScale+ ZU19EG框图
-
CPU#1 & CPU2 总运算能力:2.24 x 1.5 x 1000 x 4 + 2.0 x 600 x2 ~= 15840 DMIPS
-
Note: Cortex-R5 : 1.67 / 2.02 / 2.45 DMIPS/MHz
Corte-A53: 2.24 DMIPS/MHz
五、FPGA 架构的灵活性
目前通用的认知是Level3的自动驾驶需要系统拥有~350,000DMIPS的运算能力,才可能实现比如雷达/视频的处理,主动避让,自动泊车等。以上章节所说的MPSoc+FPGA已经有足够的计算能力足以支持Level3左右的自动驾驶在一般场景下的运用。
然而为了支持更多的自动驾驶Level4/Level5的场景,由于FPGA的接口灵活性,很容易在和FPGA的基础上额外增加子计算模块,整个系统运算能力将突飞猛进,这样极大地方便了平衡运算力到不同的运算单元。
比如:可以把激光雷达的数据处理单独放到某一个Intel Xeon 子计算模块执行,FPGA母板只需要控制逻辑,把激光雷达数据通过高速接口(PCIe或者10G以太网)传递给子计算模块让其进行大量的数据处理。
FPGA的灵活性可以让开发者拓展出越来越多的可能。













获取更多评论