毫米波雷达和「图像数据」的融合|技术解读篇
文章来源: 焉知新能源汽车
发布时间:2021-06-24
随着毫米波雷达在自动驾驶车辆中越来越多的应用,它的数据如何与图像进行融合,也成为了一个亟需解决的问题。
作者言:
由于工作的关系,一直关注自动驾驶技术中的传感器感知算法,平时会读相关的论文,跟踪学术界和工业界最新的进展。
自动驾驶是近些年来非常火热的方向,感知技术也是日新月异的发展,因此有必要系统性的梳理技术的脉络,一方面方便自己随时查阅,另一方面也期望和同道中人多多交流。
自动驾驶的应用中通常会包括多种传感器,以提高系统的可靠性。
从目前来看,常用的传感器包括可见光相机,激光雷达和毫米波雷达。这些传感器各有优缺点,也互为补充,因此如何高效的融合多传感器数据,也就自然的成为了感知算法研究的热点之一。
毫米波雷达感知算法的研究起步较晚,公开的数据库也不多,因此,目前多传感器融合的研究主要集中在融合相机(图像)和激光雷达(点云)的数据。
随着毫米波雷达在自动驾驶车辆中越来越多的应用,它的数据如何与图像进行融合,也成为了一个亟需解决的问题。
毫米波雷达的数据一般以 Point Cloud(点云)的形式呈现。理论上说这与激光雷达的点云类似,只是每个点包含的数据不同:激光雷达的点包括 X、Y、Z 坐标和反射信号强度;而毫米波雷达的点包括 X、Y(也可能有 Z)坐标,RCS(物体反射面积)和 Doppler(物体速度)。
因此,很多激光雷达和图像的融合方法也可以用来融合毫米波雷达。
但相对于激光雷达,毫米波雷达的点云非常稀疏(几十 vs 几千),所以在算法上还需要一些特殊的设计。
目前来看,大多数融合算法采用点云数据作为输入,但是也有部分工作采用更底层的雷达数据,比如 Range-Doppler-Azimuth (RAD)Tensor。RAD 数据包含更多的信息,需要的运算量也更大,但是对于深度学习来说,RAD 是更适合的数据。
下面会分别介绍基于这两种数据的融合方法,并对其中存在的问题和未来的发展方向进行分析。
一、基于 Point Cloud 的融合方法
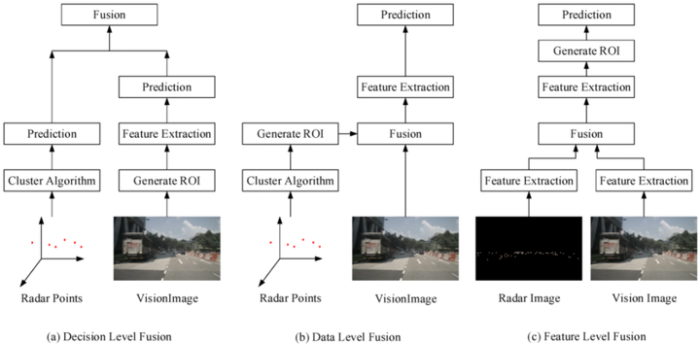
按照融合层次的不同,这类方法又可以分为 Feature-level Fusion(特征层融合)、Data-level Fusion (数据层融合)和 Decision-level Fusion (决策层融合)。
决策层的融合其实就是分别处理雷达和图像数据,将两种数据中得到的结果进行融合。这种方法需要考虑的是如何将不同可信度的结果整合到一起,采用的多是传统的基于滤波的策略。由于并没有充分考虑特征层面的互补性,这种方法对系统性能的提升有限。
数据层融合
其实这种方法叫做特征 + 决策融合更贴切一些,因为其核心思想是由一种传感器数据生成目标物体的候选(术语称作 Proposal),然后在另外一种传感器数据上进行验证。
这也就相当于融合了一种传感器的决策(Proposal)和另外一种传感器的数据。
一般来说,由于雷达点云已经很接近于物体检测的结果,Proposal 会基于点云来生成。
你可以理解为一个点就是一个物体 Proposal 或者对点云做一个简单的聚类,每个类作为一个物体,然后将生成的 Proposal 从雷达坐标系(一般是 Bird's Eye View, BEV)映射到图像坐标系,并根据 Proposal 的距离来生成候选的 Boundingbox。
最后就是用传统的基于 CNN 的方法(比如 Faster RCNN)来对 Proposal 进行分类。
更复杂一些的方法会先将点云转换成 BEV 坐标下的图像,采用基于 CNN 的物体检测网络生成 Proposal,与直接由点云生成 Proposal 相比,基于 BEV 图像的方法增加了计算量,但一般来说生成的 Proposal 质量会高很多,毕竟 CNN 可以从点云中抽取更为丰富的物体和场景信息。
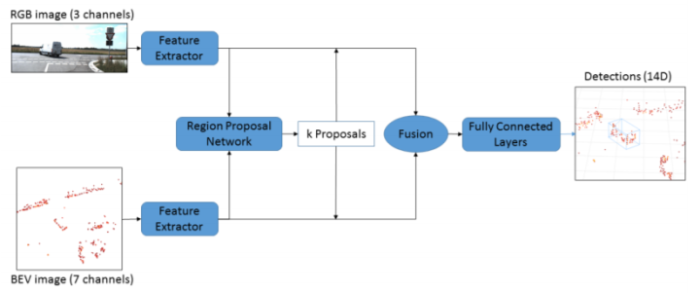
也有人提出通过雷达 BEV 数据和相机图像数据同时生成 Proposall。来自两种数据的 Proposal 通过几何映射可以进行对应,然后再将各自的特征进行融合,用全连接网络进行分类。这里的几何映射指的是BEV和图像坐标之间的映射,可以由雷达和相机的标定数据计算得到。
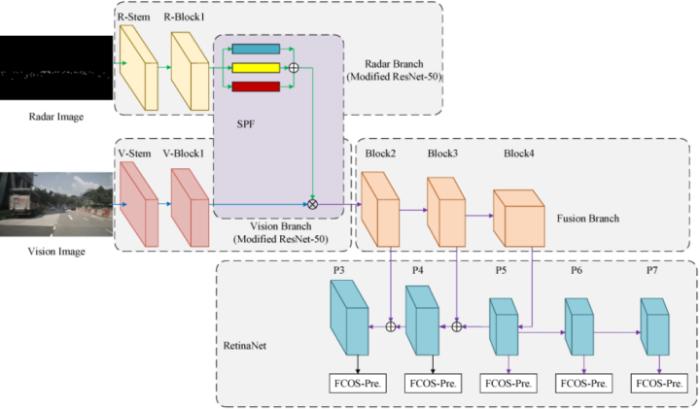
特征层融合
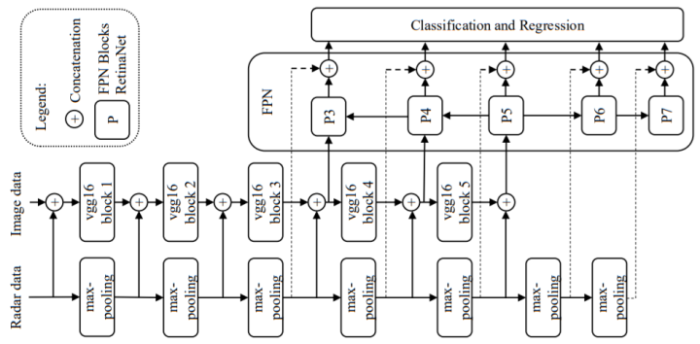
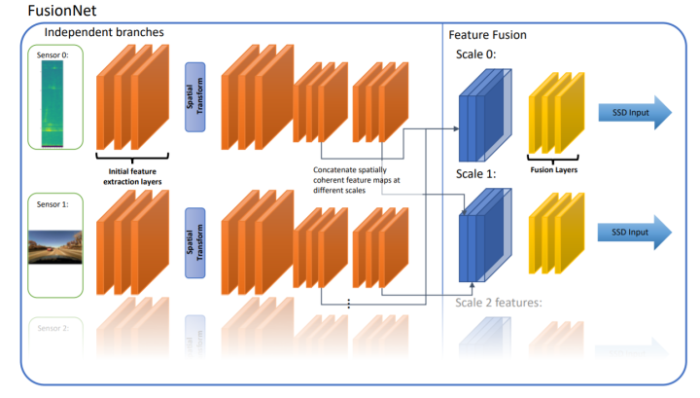
与数据层融合相比,特征层的融合更加底层一些,也更有利于神经网络也学习不同传感器之间的互补性,但是算法设计的复杂程度也相对较高。一般的做法是将点云数据映射到图像坐标系下,形成一个类似于相机图像的「点云图像」。
比如在下图中的例子中,第一行是相机图像,第二、三行是对应 Range 和 Doppler 数据的点云图像,分别反映了场景内物体的距离和运动信息。点云图像和相机图像处于相同的坐标系下,因此,可以很容易的通过神经网络进行融合。
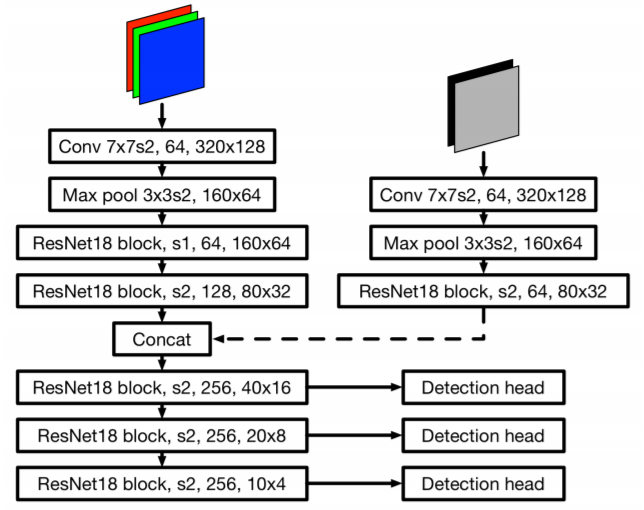
也可以将包含 Range 和 Doppler 的点云图像作为额外的输入数据,用 ResNet 进行特征提取后与相机 RGB 图像进行融合。
这里所谓的融合其实就是一个简单的 Concatenation 操作,这是深度学习中一个常见的操作,它将来自多个输入的特征图叠放到一起,后续一般会采用 kernel 大小为 1 x 1 的卷积层对其进行压缩,其实也就是一个加权平均的过程。网络会自动的从训练数据中学习权重,从而达到融合多种特征的目的。
特征融合模块输出的是特征图,因此后续我们可以采用一些标准的网络结构来完成想做的任务,比如物体检测或者语义分割。在下图的例子中,融合模块输出的特征图经过 ResNet 和下采样来提取多分辨率下的特征。每种分辨率的特征图分别连接了 detection head 来完成物体检测的任务。
类似的方法有很多,比如将点云的 Range 和 Doppler 信息投影到图像坐标系,采用 concat 操作来融合来自雷达和图像的特征,只不过后续的物体检测采用了 YOLO 网络。
做数据的融合方法很多,也可以利用点云的 Range 和 RCS 信息,将其投影到图像坐标系下,得到基于 Range 和 RCS 的点云图像。这些操作与之前介绍的方法基本没有区别,但是这样处理了两个重要的问题:
一,传统毫米波雷达的点云数据非常稀疏,生成的点云图像包含的信息量也很少,不利于神经网络的特征学习。
其实在传统的雷达数据处理中,单帧的点云数据也是很难处理的,一般都需要在时序上进行融合,比如 Occupancy grid 中的做法。类似的,也有将多帧的点云 1 秒钟的跨度进行融合,以提高数据的稠密度,与 Occupancy grid 中的做法类似,我们需要对多帧的点云进行 Ego motion 的补偿,使其处于统一的坐标系下。
这里需要注意的是,ego motion 的补偿只对静态物体有效,对于运动物体来说,运动的轨迹会出现在融合后的点云中。
二,特征融合的一个重要参数就是在网络的哪一层上进行融合。
这个参数一般都是通过经验或者实验来确定。这篇文章提出了一个新的方法,也就是将雷达数据和图像数据在不同层上分别进行融合,最后由网络通过学习来决定不同层次上融合的权重。
在前面介绍的方法中,不管是在单一层上,还是多层上进行融合,基本的操作都是采用 Concat 将多种数据叠放在一起并由网络进行加权平均。
这种做法可以通过学习得到不同传感器数据的权重,但是这些权重是全局性的,无法反映局部区域的重要性。举个不太严谨的例子,在自动驾驶的应用中,车辆正前方近处的物体其重要性要远大于侧面远处的物体,为了体现这种局部区域的重要性区别,可利用注意力机制来对特征图的不同位置进行加权。
具体来说,还是通过几何映射生成雷达点云图像,这个图像经过一系列网络操作后生成 Attention map,并将其与相机图像生成的特征图相乘。这里的相乘操作是对每一个像素分别进行的,也就相当于用 Attention map 上的每一个像素值对图像特征图的对应像素进行加权,
Attention map 上像素值的大小反映了该区域的重要程度。
经过 Attention map 的加权后,我们得到的数据依然是以特征图的形式存在。
值得一提的是,将 Attention map 与其他融合方法进行实验对比后,比如 Multiply,Add,Concatenation。结论是基于 Attention map的方法在物体检测的效果上显著的优于其他融合方法。
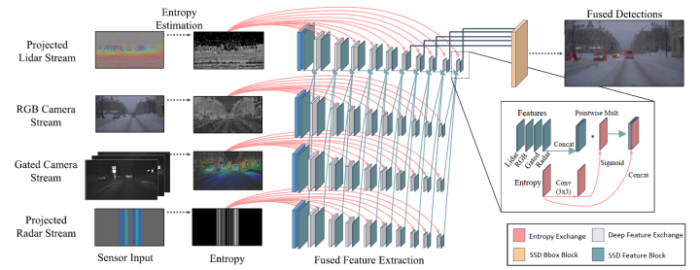
在查阅的资料中有的 Attention map 由雷达数据生成,但是理论上说每种传感器数据都可以生成 Attention map。具体来说,该方法将所有同步的传感器的数据(可见光相机、近红外相机、激光雷达、毫米波雷达)映射到统一的图像坐标系下,并以此生成相应的熵图像(Entropy map)。
不同传感器的特征图通过 Concat 操作叠放到一起,并与经过 Sigmoid 处理后的熵图像进行像素点相乘操作,得到最终的特征输出。
这里所谓的熵图像可以通过对图像的局部处理得到,熵图像中的每一个像素值都反映了该局部块(16 x 16 像素)的信息熵,也就是包含信息量的大小,你也可以将其理解为一种特殊的attention map。
需要注意的是,这个局部信息熵图像并不是通过学习得到,因此可以更好的处理罕见数据(比如各种极端天气情况)。如果采用基于 Attention 的方法,那么就需要在各种天气情况下采集大量数据用于网络学习,这显然是非常费时费力的。
对于雷达点云数据,与相机图像的融合大多在较低的特征层上进行,这也是为了充分利用神经网络的特征学习能力。
前者将来自不同传感器的特征图做全局的加权平均(通过 concat 和 1 x 1 卷积实现)。后者将来自不同传感器的特征图相乘,可以理解为用某个传感器的数据对另一个传感器的数据进行局部加权。
通常来说,有用的分类信息会更多的隐藏在局部区域中,不同局部区域的重要性也不尽相同,因此相乘的方式一般会取得更好的结果。
二、基于 RAD Tensor 的融合方法
通常来说,毫米波雷达的点云都非常稀疏,很多有用的信息已经在雷达信号处理的过程中被过滤掉了。因此,毫米波雷达感知算法的研究开始慢慢转向直接利用深度神经网络处理雷达的底层数据,比如 Range-Azimuth-Doppler Tensor。
那么,将 RAD 数据与相机图像数据进行融合,也就自然的成为了新的研究增长点。
将 RAD 数据(极坐标)和图像数据都转换到 BEV 坐标(笛卡尔坐标系)下。RAD 其实可以看作极坐标下的多通道图像,其通道是 Doppler 特征,做完坐标转换之后就可以看作 BEV 下的多通道的图像。
同样的,相机图像做完坐标转换后也可以看作 BEV 下的多通道(比如 RGB)图像。
两种数据处于同一坐标系下,后续的处理就相对简单了:比如基于 Concat 的方式将两种数据在多尺度上进行了融合。
这个方法本身没有太多可介绍之处,但其中两个实际应用中的问题值得讨论一下:
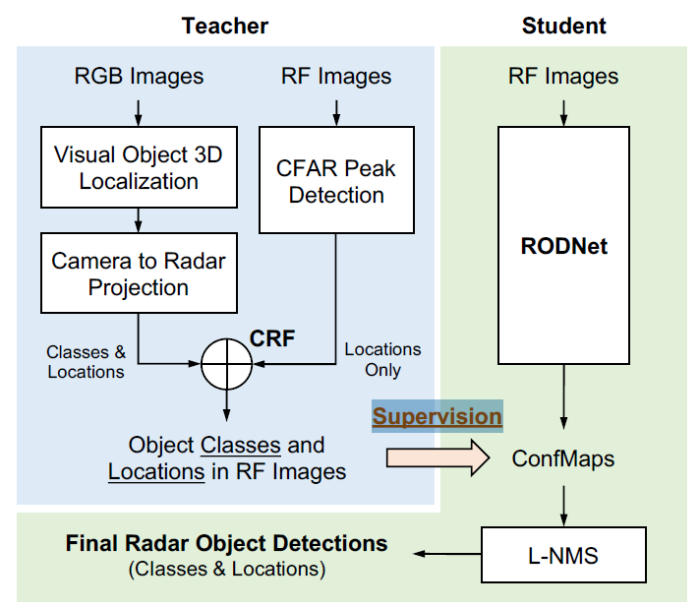
在美国有工程师提出的 RODNet 是一个较新的工作,并且在公开数据库 CRUW 上进行了测试。
实际上,这个工作的融合部分在于利用多传感器数据生成标注信息,也就是下图中的 Teacher 分支。对于网络预测部分,也就是下图中的 Student 分支,图像数据并没有参与。对于 Teacher 分支,基于 RGB 图像的物体检测结果与雷达点云(也就是 CFAR detection)相结合,得到物体的标注,用于训练检测网络。
至于 Student 分支,其实就是一个基于底层雷达数据的物体检测网络。当然这里面有一些特别的设计。比如说,输入数据并不是标准的 RAD,而是 Range-Azimuth-Chirp Tensor。
在通常的雷达信号处理中,对 Chirp 维度做 FFT 会得到 Doppler 信息,但是这个工程师采用神经网络来做这一步,以期更好的提取物体的运动信息。
基于雷达 RAD 数据的深度学习算法研究刚刚起步,因此融合 RAD 和图像数据的方法也并不多,以上方法分别算是在特征融合和数据融合上做的比较好的工作。
三、未来发展趋势
总的来说,融合毫米波雷达和图像数据的研究工作不是很多,其中大多数方法采用雷达点云数据,将其映射到图像坐标系下后再与相机数据进行融合。
这种方式相对于图像检测网络来说,附加的计算量的较少,对雷达硬件的要求的也相对较低。
但是毫米波雷达的点云非常稀疏,包含的信息量有限,因此采用更加底层的雷达数据将会成为接下来的主流研究方向。
个人认为,作为未来的发展方向,融合底层雷达数据和图像数据的算法至少还需要解决以下问题:
一,坐标统一问题。
雷达 RAD 数据是 BEV 坐标,而图像数据则是透视坐标,如何将两种数据映射到统一的坐标系下是设计融合算法的关键。有企业将相机图像映射到 BEV 坐标,但是可以看到转换后的图像有很大的畸变,不利于提取物体信息。
另外一种可能是将雷达数据看做稠密的点云,并将其映射到图像坐标下。
二,数据同质问题。
即使将雷达和图像数据映射到一个坐标系下,其数据本身也存在着巨大的差异。需要设计不同的网络结构来对不同质的数据进行处理,使其在统计分布上尽可能的一致。只有这样,后续的融合才有可能带来性能的提升。
三,时序对齐问题。
由于不同传感器的采样频率不同,各传感器的数据之间会有一定的时间差。这会带来数据的不一致性,尤其是在车辆或目标物体高速运动的情况下。

















获取更多评论